☰
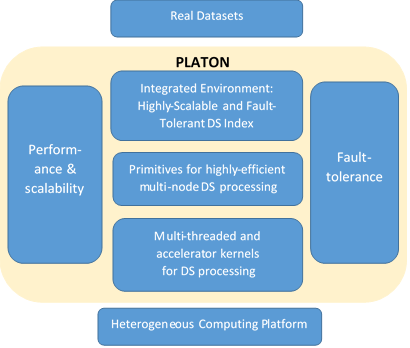
Figure 1. The proposed components of PLATON
The architecture of PLATON is shown in Figure 1. The work to be accomplished falls under the three following directions:
Research Direction 1. PLATON will provide query-aware data partitioning and mapping mechanisms to perform the index creation and the execution of queries on multiple nodes. It will also come up with a set of communication and synchronization primitives to enable the orchestration of the computation on different nodes. Existing state-of-the-art techniques perform data partitioning in a query-agnostic way, thus facing serious load balancing problems during query answering. Moreover, we will develop mechanisms that will ensure fault-tolerance in the presence of node failures.
Research Direction 2. In this research direction, we will build data series processing accelerator kernels (targeting GPU devices), and a set of multi-threaded indexing structures and query processing techniques to enhance NUMA-awareness and add fault-tolerance on top of existing state-of-the-art parallel indexes (that utilize locks and thus block in the presence of failures).
Research Direction 3. We will integrate the software described above to come up with a highly-efficient index for large-scale processing of data series. The resulting index will utilize, for the first time, all the resources provided by modern computing platforms. We will evaluate and demonstrate the performance capabilities of the PLATON index on top of real datasets.PLATON will go beyond the state-of-the-art data series indexing schemes in the following ways:
Botao Peng, Panagiota Fatourou, and Themis Palpanas, "ParIS+: Data Series Indexing on Modern Hardware", IEEE Transactions on Knowledge and Data Engineering, doi: 10.1109/TKDE.2020.2975180. (a preliminary version of this work appears in Proceedings of the IEEE International Conference on Big Data (BigData’18), pp. 791-800, Seattle, WA, USA, December 2018).
We present the Parallel Index for Sequences (ParIS), the first data series index that inherently takes advantage of modern hardware parallelization, and incorporate the state-of-the-art techniques in sequence indexing, in order to accelerate processing times. ParIS, which is a disk-based index, can effectively take advantage of multi-core and multi-socket architectures, in order to distribute and execute in parallel the computations needed for both index construction and query answering. Moreover, ParIS exploits the Single Instruction Multiple Data (SIMD) capabilities of modern CPUs, in order to further parallelize the execution of individual instructions inside each core. Overall, ParIS achieves very good overlap of the CPU computation with the required disk I/O.
We extend ParIS to get ParIS+, an alternative of ParIS that results in index creation that is purely I/O bounded. ParIS+ is 2.6x faster than the current state-of-the-art approach. ParIS and ParIS+ employ the same algorithmic techniques for query answering. Experiments demonstrate their effectiveness in exact query answering: they are up to 1 order of magnitude faster than the state-of-the-art index scan method, and up to 3 orders of magnitude faster than the state-of-the-art optimized serial scan.
In developing ParIS+ (and ParIS), we made careful design choices in the coordination of the compute and I/O tasks, and consequently, developed new algorithms for the construction of the index and for answering similarity search queries on this index. For query answering in particular, we studied alternative solutions, and evaluated the trade-off between execution speed and the amount of communication among the parallel worker threads, which affects the effectiveness of each individual worker.
Botao Peng, Panagiota Fatourou, and Themis Palpanas, “MESSI: In-Memory Data Series Indexing”, Proceedings of the 36th IEEE International Conference on Data Engineering (ICDE’20), pp. 337-348, Dallas, Texas, April 2020 (also submitted to VLDB Journal).
In this work, the focus is on designing an efficient parallel indexing and query answering scheme for in-memory data series processing. We present MESSI, an in-MEmory data SerieS Index that incorporates the state-of-the-art techniques in sequence indexing and inherently takes advantage of modern hardware parallelization in order to accelerate processing times. MESSI supports similarity search queries on both z-normalized and non z-normalized data, using both the Euclidean and the Dynamic Time Warping (DTW) distance measures. MESSI features redesigned algorithms that lead to a further ~4x speedup in index construction time, in comparison to an in-memory version of ParIS+. Furthermore, MESSI answers exact 1-NN queries on 100GB datasets 6-11x faster than ParIS+ across the datasets we tested, achieving for the first time interactive exact query answering times, at ~50msec.
When building ParIS+, the design decisions were heavily influenced by the fact that the cost was mainly I/O bounded. Since MESSI copes with in-memory data series, no CPU cost can be hidden under I/O. Therefore, MESSI required more careful design choices and coordination of the parallel workers. This led to the development of a more subtle design for the construction of the index and on the development of new algorithms for answering similarity search queries on this index.
Botao Peng, Panagiota Fatourou, Themis Palpanas, “SING: Parallel In-Memory Sequence Indexing Using GPU’’, Proceedings of the 37th IEEE International Conference on Data Engineering (ICDE’21), appeared as a poster.
In this work, we propose SING, the first data series index designed to take advantage of Graphics Processing Units (GPUs). SING is an in-memory index that uses the GPU's parallelization opportunities (as well as SIMD, multi-core and multi-socket), in order to accelerate similarity search.
We conduct an experimental evaluation with several synthetic and real datasets, which shows that SING is up to 5.1x faster than the state-of-the-art parallel in-memory approach, and up to 62x faster than the state-of-the-art parallel serial scan algorithm. SING achieves exact similarity search query times as low as 32msec on 100GB datasets, which enables interactive data exploration on very large data series collections.
![]()
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 101031688.